Deploying Data Refinery
This document will work through the intricate steps to deploy Data Refinery into an Amazon Web Services (AWS) account. Prerequisites are detailed below to assist with user set-up for deployment.
Table of contents
Prerequisites
The following information provides in-depth details on what is needed before getting started with Data Refinery. This includes steps on AWS account creation and purchasing or configuring a domain.
AWS Account Creation
To install Data Refinery, an AWS account is required. If the AWS account is part of an AWS Organization, then the account must have permissions to manage multiple services including:
- AWS Elastic Container Service
- AWS Elastic Container Registry
- AWS Elastic Load Balancing
- AWS Elastic Cloud Compute
- AWS Simple Storage Service (S3)
- AWS Secrets Manager
- AWS Identity Access Management
- AWS Relational Database Service
- AWS Glue
- AWS Redshift
- AWS Key Management Service
- AWS Route53
- AWS CloudWatch
- AWS Simple Notification Service
- AWS Global Accelerator
- AWS Bedrock
If a current AWS account is not available for use, ensure that any account created follows AWS’s Best Practices outlined in the AWS Account Management Reference Guide and the AWS New User Guide. This is necessary to secure the account before uploading any protected data.
Purchase or Configure a Domain in AWS
To ensure that users can access Data Refinery, each installation uses a “domain” for hosting the application. The recommended setup is to purchase a domain through AWS’s “Route53” service, which will ensure the domain is automatically renewed and properly configured. For documentation on how to purchase a domain via Route53, see Amazon’s documentation.
If an existing domain that is purchased elsewhere is used for hosting Data Refinery, please consult Kingland Support for assistance with configuring the external domain.
Manually Enable AI Models
Once an AWS account has been created, enabling AI Models through Amazon Bedrock is required to process Documentation Sources. Without enabling an AI model like Claude, for example, documentation attributes will not be extracted from Documentation Sources in Data Refinery. Therefore, these Documentation Sources will not be queryable.
A user can enable Amazon Bedrock models by navigating to their AWS Console.
- Log in to the AWS Console.
- Navigate to Amazon Bedrock, or click here.
- Click Model Access under “Bedrock Configurations” located in the left vertical navigation.
-
A list of Base models will appear. A user can enable one of the Base models listed or search for a model.
Under the “Access Status” column of the Base models list, a user can click Available to request then Request model access depending on the user’s permissions.
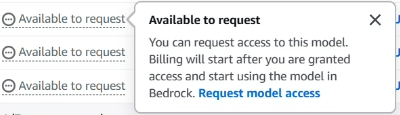
Data Refinery currently uses the
Claude 4.5 Sonnetmodel, which must be enabled at a minimum. Enabling other model versions is optional. -
AWS will prompt the user to explain the reason to enable Claude models. Provide the following rationale, or something similar:
“We are using Anthropic Claude to extract key data attributes from unstructured data in documents.”
- Once a request has been made to AWS to enable a model, an approval should be given within approximately 10-15 minutes and grant access to the model.
Deploying Data Refinery
This section covers the process for working alongside Kingland to deploy an instance of Data Refinery. The deployment itself, as well as any deployments for updates, will be handled by Kingland, but Kingland will require some information before conducting the initial deployment.
Information Collection
Kingland will require the following information in order to deploy Data Refinery.
- The AWS account ID that will be deployed to.
- The region that should be deployed to.
- Note that some resources (such as domain names) are required to be deployed to us-east-1, but most resources and all data will be deployed to the specified region.
- The domain that Data Refinery will be served from.
- The subdomain (usage) that should be used for the deployment (dev, prod, www, etc.).
Provide the above information when prompted by a Kingland representative.
Deploy IAM Role
A Kingland representative will provide a Cloudformation YAML file for an IAM role. For more information of Cloudformation, see Amazon’s documentation. The IAM role will give Kingland permission to create and manage resources in the provided AWS account. The exact permissions and their reason for inclusion is outlined in Appendix A: IAM Role Permissions.
After receiving the Cloudformation YAML file, it will need to be uploaded to the AWS account and the stack deployed. The process below outlines how this is accomplished.
- Log in to the AWS Console.
- Navigate to the CloudFormation Service, or click here.
- Click Create Stack in the upper right of the page. If prompted, select With new resources.
- On the “Create Stack” page, select Choose an Existing Template which will be the pre-selected option, then select Upload a Template File.
- Upload the file provided by Kingland.
- Click Next.
- Provide a name for the stack - “Data-Refinery-Deployment-Role” is the name that Kingland recommends.
- Leave all the settings on the next page as their default options. Select the checkbox acknowledging CloudFormation will create IAM resources.
- Click Next.
- Leave all the settings on the next page as their default options. Scroll to the bottom of the page and click Submit.
A new page will be shown at this point that details the Role creation process. Creating all the roles and permissions should take approximately 2-5 minutes. After the role creation is complete, let Kingland know that the role has been successfully created, and Kingland will continue the deployment.
Environment Customizations
Data Refinery contains several attributes that may be modified to accommodate specific use cases. The relevant attributes are provided below in Appendix B: Environment Customization Options. Notify a Kingland representative if any of these attributes should be modified.
All attributes may be customized on initial deployment or on a subsequent deployment by notifying your Kingland Customer Support representative.
Environment Deployment
Once the required information has been provided, the Kingland IAM role deployed, and any customizations setup, Data Refinery will be ready for deployment. Work with a Kingland representative to coordinate the timing of the deployment, and the representative will ensure Data Refinery is deployed.
Post Deployment
This section covers post deployment details relevant to access in Data Refinery to get started. The deployed instances of Data Refinery will be accessible at https://{usage}.{domain}, which were described in the previous section.
Passwords
After a successful deployment, Data Refinery will be accessible. A default “system_admin” user will be created to facilitate the initial creation of Users, Projects, and Sources. The “system_admin” user password, RDS database password, and Redshift admin password are stored in AWS Secrets Manager under the following names:
| Password | Secret Name (prefix) |
|---|---|
| API “system_admin” user | api_admin_password_{usage} |
| API DB Password | api_database_password_{usage} |
| Redshift DB Password | redshift_password_{usage} |
To retrieve the values for these passwords, follow these steps:
- Log in to the AWS Console.
- Navigate to the AWS Secrets Manager page, or Click Here
- If no secrets show up, select the correct AWS Region in the upper right corner
To retrieve the value for the system_admin user, select the secret with the api_admin_password prefix. If multiple environments are deployed, each secret will have the environment name at the end of it.
After clicking on the secret, select Retrieve secret value, and the password will be displayed.
Licensing
With Data Refinery deployed, a license may be installed. Follow How to Install a License in DR Designer for information on installing a license.
Appendices
Appendix A: IAM Role Permissions
Below are the permissions that are granted to the KinglandDataRefineryDeployRole role organized by AWS service. Each permission category includes a description of what the deployment will use the permission for.
IAM Service
IAM permissions are required because least-privileged IAM roles are created for individual components of Data Refinery to ensure that each component has the minimal number of permissions that it needs.
For more information on the permissions below, see Amazon’s documentation.
- iam:CreatePolicy:
- iam:DeletePolicy:
- iam:GetPolicy:
- iam:GetPolicyVersion:
- iam:ListPolicyVersions:
- iam:AttachRolePolicy:
- iam:UpdateAssumeRolePolicy:
- iam:CreateRole:
- iam:CreateServiceLinkedRole:
- iam:DeleteRole:
- iam:DeleteRolePolicy:
- iam:DetachRolePolicy:
- iam:GetRole:
- iam:GetRolePolicy:
- iam:ListAttachedRolePolicies:
- iam:ListInstanceProfilesForRole:
- iam:ListRolePolicies:
- iam:PutRolePolicy:
- iam:TagPolicy:
- iam:TagRole:
- iam:UntagPolicy:
- iam:UntagRole:
- iam:PassRole:
- iam:ListPolicies:
- iam:ListRoles:
Glue Service
Glue is used to determine which columns are present for individual Sources, and to keep the information about Source versions and columns up-to-date. The permissions below allow the deployment role to create the tables and classifiers necessary to ensure that queries against the Sources work properly.
For more information on the permissions below, see Amazon’s documentation.
- glue:BatchCreatePartition:
- glue:BatchDeletePartition:
- glue:BatchDeleteTable:
- glue:BatchDeleteTableVersion:
- glue:BatchGetCrawlers:
- glue:BatchGetPartition:
- glue:CreateClassifier:
- glue:CreateCrawler:
- glue:CreateDatabase:
- glue:CreatePartition:
- glue:CreateTable:
- glue:DeleteClassifier:
- glue:DeleteCrawler:
- glue:DeleteDatabase:
- glue:DeletePartition:
- glue:DeleteTable:
- glue:GetClassifier:
- glue:GetClassifiers:
- glue:GetCrawler:
- glue:GetCrawlers:
- glue:GetDatabase:
- glue:GetDatabases:
- glue:GetPartition:
- glue:GetPartitions:
- glue:GetSchema:
- glue:GetTable:
- glue:GetTableVersion:
- glue:GetTableVersions:
- glue:GetTables:
- glue:GetTags:
- glue:ListCrawlers:
- glue:StartCrawler:
- glue:TagResource:
- glue:UntagResource:
- glue:UpdateClassifier:
- glue:UpdateCrawler:
- glue:UpdateDatabase:
- glue:UpdateTable:
STS Service
STS permissions relate to how roles are passed between services. GetCallerIdentity is used by the deployment process to obtain generic metadata about the account, such as the numeric account ID.
For more information on the permissions below, see Amazon’s documentation.
- sts:AssumeRole:
- sts:GetCallerIdentity:
Cloudwatch Service
CloudWatch is used both for monitoring of the deployment, along with ensuring that new resources are automatically added to the environment as needed.
For more information on the permissions below, see Amazon’s documentation.
- cloudwatch:DeleteAlarms:
- cloudwatch:DescribeAlarms:
- cloudwatch:DescribeAlarmsForMetric:
- cloudwatch:ListTagsForResource:
- cloudwatch:PutCompositeAlarm:
- cloudwatch:PutMetricAlarm:
- cloudwatch:TagResource:
- cloudwatch:UntagResource:
EC2 Service
While no EC2 instances are created by Data Refinery, EC2 permissions are still needed for creating networks, firewalls, and listing which Availability Zones are enabled in the account’s current Region. These Permissions are used to determine which network subnets are used for databases, containers, load balancers, and more.
For more information on the permissions below, see Amazon’s documentation.
- ec2:CreateTags:
- ec2:DescribeTags:
- ec2:DescribeAccountAttributes:
- ec2:DescribeAvailabilityZones:
- ec2:DescribeInternetGateways:
- ec2:DescribeNetworkInterfaces:
- ec2:DescribePrefixLists:
- ec2:DescribeRouteTables:
- ec2:DescribeSecurityGroupRules:
- ec2:DescribeSecurityGroups:
- ec2:DescribeSubnets:
- ec2:DescribeVpcEndpoints:
- ec2:DescribeVpcs:
- ec2:DescribeVpcAttribute:
- ec2:AuthorizeSecurityGroupEgress:
- ec2:AuthorizeSecurityGroupIngress:
- ec2:CreateSecurityGroup:
- ec2:DeleteSecurityGroup:
- ec2:RevokeSecurityGroupEgress:
- ec2:RevokeSecurityGroupIngress:
- ec2:CreateVpc:
- ec2:DeleteVpc:
- ec2:DescribeVpcs:
- ec2:CreateSubnet:
- ec2:DeleteSubnet:
- ec2:DescribeSubnets:
- ec2:CreateRouteTable:
- ec2:DeleteRouteTable:
- ec2:AssociateRouteTable:
- ec2:DisassociateRouteTable:
- ec2:DescribeRouteTables:
- ec2:CreateRoute:
- ec2:ReplaceRoute:
- ec2:DeleteRoute:
- ec2:CreateInternetGateway:
- ec2:AttachInternetGateway:
- ec2:DetachInternetGateway:
- ec2:DeleteInternetGateway:
- ec2:DescribeInternetGateways:
- ec2:CreateNatGateway:
- ec2:DeleteNatGateway:
- ec2:DescribeNatGateways:
- ec2:AllocateAddress:
- ec2:ReleaseAddress:
- ec2:AssociateAddress:
- ec2:DisassociateAddress:
- ec2:DescribeAddresses:
- ec2:CreateSecurityGroup:
- ec2:DeleteSecurityGroup:
- ec2:DescribeSecurityGroups:
- ec2:AuthorizeSecurityGroupIngress:
- ec2:RevokeSecurityGroupIngress:
- ec2:AuthorizeSecurityGroupEgress:
- ec2:RevokeSecurityGroupEgress:
- ec2:CreateVpcEndpoint:
- ec2:DeleteVpcEndpoints:
- ec2:DescribeVpcEndpoints:
- ec2:CreateFlowLogs:
- ec2:DeleteFlowLogs:
- ec2:DescribeFlowLogs:
- ec2:CreateFlowLogs:
- ec2:DeleteFlowLogs:
- ec2:DescribeFlowLogs:
- ec2:DescribeNetworkInterfaces:
ECS Service
ECS permissions are used for deploying the containers that run the APIs, documentation sites, and background tasks.
For more information on the permissions below, see Amazon’s documentation.
- ecs:CreateCapacityProvider:
- ecs:CreateCluster:
- ecs:CreateService:
- ecs:CreateTaskSet:
- ecs:DeleteAttributes:
- ecs:DeleteCapacityProvider:
- ecs:DeleteCluster:
- ecs:DeleteService:
- ecs:DeleteTaskDefinitions:
- ecs:DeleteTaskSet:
- ecs:DeregisterTaskDefinition:
- ecs:DescribeCapacityProviders:
- ecs:DescribeClusters:
- ecs:DescribeServices:
- ecs:DescribeTaskDefinition:
- ecs:DescribeTaskSets:
- ecs:ListAttributes:
- ecs:ListClusters:
- ecs:ListServices:
- ecs:ListServicesByNamespace:
- ecs:ListTagsForResource:
- ecs:ListTaskDefinitions:
- ecs:ListTaskDefinitionFamilies:
- ecs:PutAttributes:
- ecs:PutClusterCapacityProviders:
- ecs:RegisterTaskDefinition:
- ecs:StartTask:
- ecs:StopTask:
- ecs:TagResource:
- ecs:UntagResource:
- ecs:UpdateCapacityProvider:
- ecs:UpdateCluster:
- ecs:UpdateClusterSettings:
- ecs:UpdateService:
- ecs:UpdateServicePrimaryTaskSet:
- ecs:UpdateTaskSet:
ECR Service
ECR permissions are used for creating container repositories and the pull-through-caches that are used for deploying the containers for each component. Caches are used to increase the speed of scaling, which improves user experience.
For more information on the permissions below, see Amazon’s documentation.
- ecr:CreatePullThroughCacheRule:
- ecr:DeletePullThroughCacheRule:
- ecr:DescribePullThroughCacheRules:
- ecr:GetAuthorizationToken:
- ecr:BatchCheckLayerAvailability:
- ecr:BatchGetImage:
- ecr:CompleteLayerUpload:
- ecr:CreateRepository:
- ecr:DeleteLifecyclePolicy:
- ecr:DeleteRepository:
- ecr:DescribeRepositories:
- ecr:GetLifecyclePolicy:
- ecr:GetRepositoryPolicy:
- ecr:InitiateLayerUpload:
- ecr:ListTagsForResource:
- ecr:PutImage:
- ecr:PutLifecyclePolicy:
- ecr:SetRepositoryPolicy:
- ecr:TagResource:
- ecr:UploadLayerPart:
Batch Service
Batch handles several functions within Data Refinery Workbench, such as Import and Export. Batch jobs run based on a queue, and limit how many jobs can run at once to ensure stability of the deployment and reasonable cost control for the host account.
For more information on the permissions below, see Amazon’s documentation.
- batch:CreateComputeEnvironment:
- batch:CreateJobQueue:
- batch:DeleteComputeEnvironment:
- batch:DeleteJobQueue:
- batch:DeregisterJobDefinition:
- batch:DescribeComputeEnvironments:
- batch:DescribeJobDefinitions:
- batch:DescribeJobQueues:
- batch:ListTagsForResource:
- batch:RegisterJobDefinition:
- batch:TagResource:
- batch:UntagResource:
- batch:UpdateComputeEnvironment:
- batch:UpdateJobQueue:
RDS Service
RDS permissions are used for deploying the underlying Aurora databases that are used for tracking Metadata (in Data Refinery Designer) or Live and Workflow Data (in Data Refinery Workbench).
For more information on the permissions below, see Amazon’s documentation.
- rds:AddTagsToResource:
- rds:ListTagsForResource:
- rds:CreateDBCluster:
- rds:CreateDBClusterSnapshot:
- rds:DescribeGlobalClusters:
- rds:DescribeDBClusters:
- rds:DeleteDBCluster:
- rds:CreateDBInstance:
- rds:CreateDBSnapshot:
- rds:CreateTenantDatabase:
- rds:DeleteDBInstance:
- rds:DeleteTenantDatabase:
- rds:DescribeDBInstances:
- rds:ModifyDBCluster:
- rds:CreateDBCluster:
- rds:CreateDBSubnetGroup:
- rds:DeleteDBSubnetGroup:
- rds:DescribeDBSubnetGroups:
- rds:CreateDBSnapshot:
- rds:CreateTenantDatabase:
- rds:DeleteTenantDatabase:
Elastic Load Balancing Service
ELB permissions are used to deploy Layer 7 Application Load Balancers, which are used to route traffic to different components based on URL path. They also ensure that the application can scale to accommodate load properly.
For more information on the permissions below, see Amazon’s documentation.
- elasticloadbalancing:CreateListener:
- elasticloadbalancing:CreateLoadBalancer:
- elasticloadbalancing:CreateRule:
- elasticloadbalancing:DescribeListeners:
- elasticloadbalancing:DescribeLoadBalancerAttributes:
- elasticloadbalancing:DescribeListenerAttributes:
- elasticloadbalancing:DescribeLoadBalancers:
- elasticloadbalancing:DescribeRules:
- elasticloadbalancing:DescribeTags:
- elasticloadbalancing:DescribeTargetGroupAttributes:
- elasticloadbalancing:DescribeTargetGroups:
- elasticloadbalancing:CreateTargetGroup:
- elasticloadbalancing:DeleteTargetGroup:
- elasticloadbalancing:DeleteListener:
- elasticloadbalancing:DeleteRule:
- elasticloadbalancing:DeleteLoadBalancer:
- elasticloadbalancing:ModifyTargetGroupAttributes:
- elasticloadbalancing:ModifyLoadBalancerAttributes:
- elasticloadbalancing:ModifyRule:
- elasticloadbalancing:SetWebAcl:
- elasticloadbalancing:AddTags:
- elasticloadbalancing:RemoveTags:
S3 Service
S3 permissions are used to store data uploaded to Data Refinery Designer sources. Data is stored in S3 and partitioned according to Source versions to ensure a blend between pricing and performance of queries.
For more information on the permissions below, see Amazon’s documentation.
- s3:CreateBucket:
- s3:DeleteBucket:
- s3:GetAccelerateConfiguration:
- s3:GetBucketAcl:
- s3:GetBucketCORS:
- s3:GetBucketLogging:
- s3:GetBucketObjectLockConfiguration:
- s3:GetBucketPolicy:
- s3:GetBucketPublicAccessBlock:
- s3:GetBucketRequestPayment:
- s3:GetBucketTagging:
- s3:GetBucketVersioning:
- s3:GetBucketWebsite:
- s3:GetEncryptionConfiguration:
- s3:GetLifecycleConfiguration:
- s3:GetReplicationConfiguration:
- s3:PutBucketLogging:
- s3:PutBucketPolicy:
- s3:PutBucketPublicAccessBlock:
- s3:PutBucketTagging:
- s3:PutBucketVersioning:
- s3:PutEncryptionConfiguration:
- s3:ListBucket:
- s3:ListBucketVersions:
- s3:DeleteObjectVersion:
Redshift Serverless Service
Redshift is used to serve the analytics database in Data Refinery Designer. Serverless Redshift is used to ensure that users’ queries remain performant as the dataset scales and the number of users in the system scale. It also scales down when not in use to ensure the smallest possible cost for the host account.
For more information on the permissions below, see Amazon’s documentation.
- redshift-serverless:CreateNamespace:
- redshift-serverless:CreateWorkgroup:
- redshift-serverless:DeleteNamespace:
- redshift-serverless:DeleteWorkgroup:
- redshift-serverless:GetNamespace:
- redshift-serverless:GetWorkgroup:
- redshift-serverless:ListNamespaces:
- redshift-serverless:ListTagsForResource:
- redshift-serverless:ListWorkgroups:
- redshift-serverless:TagResource:
- redshift-serverless:UntagResource:
- redshift-serverless:UpdateNamespace:
- redshift-serverless:UpdateWorkgroup:
Cloudwatch Logs Service
CloudWatch logs are used to store logs from individual application components. All logs from containers are stored in CloudWatch logs, and some infrastructure-level logs are stored here as well.
For more information on the permissions below, see Amazon’s documentation.
- logs:CreateLogGroup:
- logs:CreateLogStream:
- logs:PutLogEvents:
- logs:DescribeLogGroups:
- logs:DescribeLogStreams:
- logs:CreateLogDelivery:
- logs:DeleteLogDelivery:
- logs:CreateLogGroup:
- logs:DeleteLogGroup:
- logs:PutRetentionPolicy:
- logs:TagResource:
- logs:UntagResource:
- logs:DeleteResourcePolicy:
- logs:DescribeLogGroups:
- logs:DescribeResourcePolicies:
- logs:ListTagsForResource:
- logs:PutResourcePolicy:
KMS Service
All data in Data Refinery is encrypted at rest using Customer Managed KMS keys so that keys may be rotated and destroyed as desired. KMS permissions allow managing those keys.
For more information on the permissions below, see Amazon’s documentation.
- kms:CreateAlias:
- kms:CreateGrant:
- kms:Decrypt:
- kms:DeleteAlias:
- kms:DescribeKey:
- kms:EnableKeyRotation:
- kms:Encrypt:
- kms:GenerateDataKey:
- kms:GetKeyPolicy:
- kms:GetKeyRotationStatus:
- kms:ListResourceTags:
- kms:PutKeyPolicy:
- kms:ScheduleKeyDeletion:
- kms:TagResource:
- kms:CreateKey:
- kms:ListAliases:
Secrets Manager Service
Secrets Manager allows storing encrypted secrets that are used to manage various Data Refinery related assets, such as Background Task credentials, database secrets, and more.
For more information on the permissions below, see Amazon’s documentation.
- secretsmanager:ListSecrets:
- secretsmanager:CreateSecret:
- secretsmanager:DeleteSecret:
- secretsmanager:DescribeSecret:
- secretsmanager:GetResourcePolicy:
- secretsmanager:GetSecretValue:
- secretsmanager:PutSecretValue:
- secretsmanager:TagResource:
Route 53 Service
Route53 is used to manage DNS routing for the solution. It will automatically update DNS routing tables, manage domain auto-renewal, and automatically create new SSL/TLS certificates as needed.
For more information on the permissions below, see Amazon’s documentation.
- route53:CreateHostedZone:
- route53:ListHostedZones:
- route53:ListTagsForResource:
- route53:GetChange:
- route53:ChangeResourceRecordSets:
- route53:ChangeTagsForResource:
- route53:CreateQueryLoggingConfig:
- route53:DeleteHostedZone:
- route53:GetHostedZone:
- route53:ListResourceRecordSets:
- route53:DeleteQueryLoggingConfig:
- route53:GetQueryLoggingConfig:
Application Auto Scaling Service
Application Autoscaling works with CloudWatch alarms and metrics to automatically provision new capacity for the environment in the event that usage on the system starts the
For more information on the permissions below, see Amazon’s documentation.
- application-autoscaling:DeleteScalingPolicy:
- application-autoscaling:DeleteScheduledAction:
- application-autoscaling:DeregisterScalableTarget:
- application-autoscaling:DescribeScalableTargets:
- application-autoscaling:DescribeScalingActivities:
- application-autoscaling:DescribeScalingPolicies:
- application-autoscaling:DescribeScheduledActions:
- application-autoscaling:ListTagsForResource:
- application-autoscaling:PutScalingPolicy:
- application-autoscaling:PutScheduledAction:
- application-autoscaling:RegisterScalableTarget:
- application-autoscaling:TagResource:
- application-autoscaling:UntagResource:
EventBridge Service
EventBridge is used to perform event-based actions. Data Refinery Designer uses EventBridge to configure read/write libraries for different file types when those files are uploaded to a Source.
For more information on the permissions below, see Amazon’s documentation.
- events:DeleteRule:
- events:DescribeRule:
- events:ListTagsForResource:
- events:ListTargetsByRule:
- events:PutRule:
- events:PutTargets:
- events:RemoveTargets:
- events:TagResource:
- events:UntagResource:
SQS Service
SQS handles the events sent by EventBridge to update read/write libraries for files that are uploaded to Sources in Data Refinery Designer.
For more information on the permissions below, see Amazon’s documentation.
- sqs:CreateQueue:
- sqs:DeleteQueue:
- sqs:GetQueueAttributes:
- sqs:GetQueueUrl:
- sqs:ListQueueTags:
- sqs:ListQueues:
- sqs:SetQueueAttributes:
- sqs:TagQueue:
- sqs:UntagQueue:
SNS Service
SNS topics are used for event-based monitoring alarms, and are used for ensuring that scaling and monitoring alarms trigger appropriately.
For more information on the permissions below, see Amazon’s documentation.
- sns:CreateTopic:
- sns:DeleteTopic:
- sns:GetTopicAttributes:
- sns:ListTagsForResource:
- sns:ListTopics:
- sns:SetTopicAttributes:
- sns:TagResource:
- sns:UntagResource:
- sns:GetSubscriptionAttributes:
ACM Service
Certificate Manager is used for issuing and maintaining TLS certificates for Data Refinery Designer and Workbench.
For more information on the permissions below, see Amazon’s documentation.
- acm:AddTagsToCertificate:
- acm:DeleteCertificate:
- acm:DescribeCertificate:
- acm:GetCertificate:
- acm:ListCertificates:
- acm:ListTagsForCertificate:
- acm:RemoveTagsFromCertificate:
- acm:RenewCertificate:
- acm:RequestCertificate:
- acm:UpdateCertificateOptions:
WAF V2 Service
The Web Application Firewall service is used by both Data Refinery Designer and Workbench to help secure the load balancers that expose the web applications.
For more information on the permissions below, see Amazon’s documentation.
- wafv2:AssociateWebACL:
- wafv2:CreateWebACL:
- wafv2:DeleteWebACL:
- wafv2:GetWebACL:
- wafv2:GetWebACLForResource:
- wafv2:ListTagsForResource:
- wafv2:TagResource:
- wafv2:UntagResource:
- wafv2:DisassociateWebACL:
- wafv2:ListTagsForResource:
SES Service
The Simple Email Service is used to send emails for Data Refinery Designer and Workbench.
For more information on the permissions below, see Amazon’s documentation.
- ses:DeleteIdentity:
- ses:GetIdentityVerificationAttributes:
- ses:VerifyDomainIdentity:
Lambda Service
Lambda is used to execute event-based code, including monitoring code and code that updates read/write libraries in Data Refinery Designer sources.
For more information on the permissions below, see Amazon’s documentation.
- lambda:AddPermission:
- lambda:CreateFunction:
- lambda:DeleteFunction:
- lambda:GetFunction:
- lambda:GetPolicy:
- lambda:ListVersionsByFunction:
- lambda:RemovePermission:
- lambda:UpdateFunctionCode:
- lambda:TagResource:
- lambda:UntagResource:
Global Accelerator Service
The Global Accelerator service is used to improve performance of applications in global deployments by ensuring priority high speed network routes are used. It’s used by Data Refinery Designer to ensure that customers who are using Background Tasks to upload large amounts of data use private network routes where possible to reduce cost.
For more information on the permissions below, see Amazon’s documentation.
- globalaccelerator:*:
AWS Systems Manager Service
Systems Manager is used for configuration management and secure parameter storage during Data Refinery deployment. These permissions allow storing and retrieving deployment configuration and secrets.
For more information on the permissions below, see Amazon’s documentation.
- ssm:GetParameter:
- ssm:GetParameters:
- ssm:PutParameter:
- ssm:DeleteParameter:
- ssm:AddTagsToResource:
- ssm:ListTagsForResource:
Amazon Bedrock Service
Amazon Bedrock is used to provide AI and machine learning capabilities within Data Refinery. These permissions allow the deployment role to interact with foundation models and manage AI-powered features.
For more information on the permissions below, see Amazon’s documentation.
- bedrock:InvokeModel:
- bedrock:GetFoundationModel:
- bedrock:ListFoundationModels:
- bedrock:TagResource:
AWS Lake Formation Service
Lake Formation provides data lake governance and security capabilities for Data Refinery. These permissions enable fine-grained access control and data governance features.
Note. While Data Refinery doesn’t directly deploy Lake Formation resources, these permissions are required for Glue Catalog integration. When Glue crawlers discover data, they automatically register with Lake Formation, which our Redshift Spectrum setup depends on.
For more information on the permissions below, see Amazon’s documentation.
- lakeformation:GetDataAccess:
- lakeformation:GrantPermissions:
- lakeformation:RevokePermissions:
- lakeformation:RegisterResource:
Appendix B: Environment Customization Options
Note. These may be updated at any time pending some time for an updated deployment. Work with a Kingland representative to further understand any attribute modifications. The defaults are usually acceptable for small to medium production environments with non-sensitive data. Sensitive data should have network protections discussed with the Kingland team to establish IP allow lists, and will be discussed during initial deployment.
| Attribute | Description | Type | Default |
|---|---|---|---|
| deploy_logging_policy | Some logging policies have strict limits in AWS. This variable controls whether those are deployed. This should be left as true unless Kingland suggests otherwise for pre-production environments. | bool | true |
| redshift_public_access | Whether the analytics database is publicly accessible. IP allow-lists can be configured for the environment to protect access to the database where the customer has static IPs available. Setting this to false requires the customer establish a VPN or private link to the account hosting Data Refinery. | bool | true |
| redshift_ingress_cidrs | Redshift will accept inbound traffic from these CIDR ranges. Should be configured with static IPs where available | list(string) | [ "0.0.0.0/0" ] |
| alb_ingress_cidrs | The Load Balancer will accept inbound traffic from these CIDR ranges | list(string) | [ "0.0.0.0/0" ] |
| drf_jwt_duration | The user JWT bearer token duration in minutes | number | 60 |
| drf_jwt_refresh_duration | The user JWT refresh token duration in minutes | number | 1440 |
| api_cpu_units | How many CPU units the API container should have. | number | 256 |
| api_memory | How many Mb of memory the API container should have. | number | 1024 |
| docs_cpu_units | How many CPU units the API docs container should have. | number | 256 |
| docs_memory | How many Mb of memory the API docs container should have. | number | 1024 |
| ecs_autoscale_min_instances | Minimum number of instances to run | number | 2 |
| ecs_autoscale_max_instances | Maximum number of instances to run | number | 10 |
| ecs_as_cpu_target_threshold_per | Desired utilization for auto scaling purposes | number | 70 |
| base_redshift_capacity | How many RPUs should be assigned as a minimum to the Redshift Serverless cluster | string | 8 |
| rds_backup_retention_in_day | How many days to store backups of the RDS metadata database | number | 7 |
| enable_vpn_gateway | Whether to create a VPN gateway | bool | false |
| glue_crawler_schedule | The CRON schedule that glue crawlers created by Data Refinery should run on after creation. Defaults to the top of every hour. More frequently will make new versions and sources queryable faster, but increases cost. | string | "0 * * * ? *" |
| gitlab_project_path | The project path in GitLab to use for ECR image pull-through. | string | "kingland-projects/data-refinery/projects/data-refinery" |
| query_pattern_image | Image name of the Query To Source docker image. | string | "default" |
| query_pattern_tag | Image tag name of the Query To Source docker image. | string | "defaultvalue" |
| ai_processor_tag | Image tag name of the ai-processor docker image. | string | "latest" |
| ai_processor_vcpu | vCPU units the AI container should have. | string | "0.25" |
| ai_processor_memory | Mb of memory for the AI container. | number | 1024 |
| drf_api_rate_limit_reset_seconds | Desired rate limit duration in seconds. | number | 1 |
| drf_api_rate_limit_requests_per_period_unauthorized | Desired rate limit for unauthorized requests per reset period. | number | 10 |
| drf_api_rate_limit_requests_per_period_authorized | Desired rate limit for authorized requests per reset period. | number | 20 |
| drf_api_rate_limit_requests_per_period_internal | Desired rate limit for internal requests per reset period. | number | 50 |