Import Live Data
Data Refinery Workbench provides import APIs to upload Live Data objects and their Attributes. The data can be imported from a standardized JSONL or Excel file. The import is asynchronous and is initiated by creating a new import request.
Table of contents
Create a New Import
To create a new import, a user must sign in to Data Refinery Workbench and navigate to the Imports page.
-
Click the Exports/Imports button in the top navigation.

-
A dropdown will appear. Select Imports.
-
On the Imports page, click Create Import.

-
Fill out the necessary fields in the “Create Import” form.
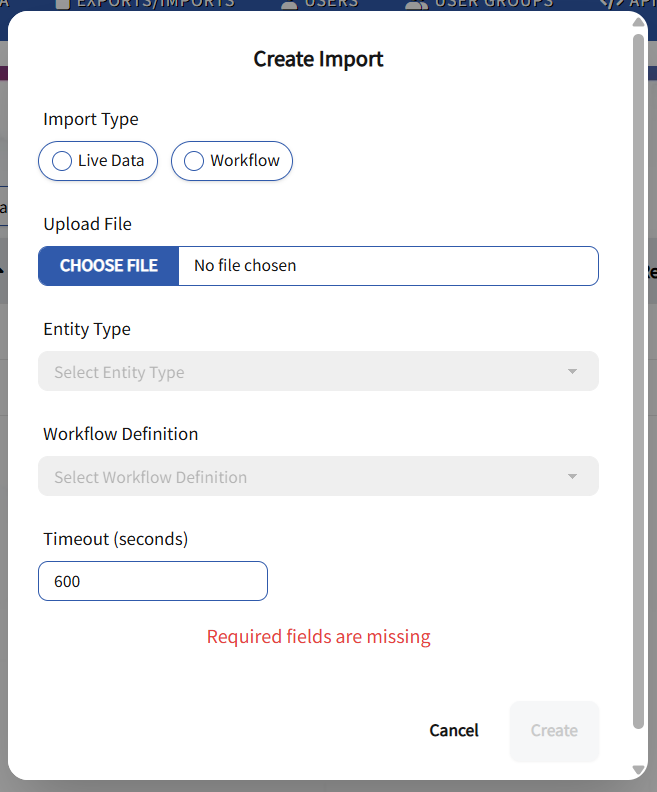
- Import Type: Required.
- Upload File: Required. File must be JSONL or an Excel file.
- Entity Type: Required if Live Data Import Type is selected.
- Workflow Definition: Required if Workflow Import Type is selected or both Live Data and Workflow Import Types are selected.
- Timeout (seconds): Default is 600 seconds. Minimum is 60 seconds.
Note. The Timeout value is the amount of time, in seconds, to allow the import job to run. Once the timeout is reached, the import job is terminated. This is an AWS mechanism to protect against endless background task executions. The import job should run to completion before this timeout is reached. The default of 600 seconds (10 minutes) is more than adequate for nearly all import jobs. If the new import is expected to take more than 10 minutes, increase Timeout to a value higher than the anticipated time to run.
-
Click Create once the “Create Import” form has been completed.
View Import Status
After the import is created, the import job is queued for processing. If there is no queue, the import job will start quickly to upload the file. Depending on the size of the data being imported, it might take some time for the data import file to be ready for upload to Workbench.
In Data Refinery Workbench, a user can view the status of the import on the Imports page. Using the “ID” or “Created Date” of the import, a user can search to view the import status displaying “In_Progress,” “Successful,” or “Failed.”
A user can click the Refresh button on the Imports page to check the progress of the import.

Create a New Import via API
The Create Import POST API submits a new request to import Live Data to Workbench. The Import Type, Workflow Definition or Entity Type ID, timeout in seconds, and Import File are needed to create (start) the import. The create import API uploads the import file to a Workbench staging area and launches the asynchronous job that processes the data. The response contains the ID of the import which is used to check its status. Refer to the DR Workbench Create Import API reference for more information.
API Parameters
The Create Import API parameters specify the data file to be imported, the type of items to create for each data record, the definition ID on which the created items are based, and the maximum duration for the asynchronous import job. This API uses form input rather than json so that it can accept a multi-part file upload. Refer to the Defining Entity Types and Defining Workflow Definitions pages for more information. Below are the API form criteria to start the import.
- importType - Required. Directs the data to live, workflow, or a combination of the two.
- entityTypeID - Required for live-only import, otherwise ignored. Unique ID of a Entity Type definition.
- workflowDefinitionID - Required for workflow or live+workflow import, otherwise ignored. Unique ID of a Workflow Definition
- timeOutInSeconds - Required. Timeout duration for the asynchronous import job. If an import job runs longer than the timeout, the job is terminated. The minimum value is 60 seconds. If the argument is not provided, or is less than 60, the default value of 600 seconds (10 minutes) is used.
- file - Required. Path to the jsonl or Excel file containing the data to import.
Note. The importType values of “live+workflow” and “workflow+live” are synonyms and do not imply any ordering. In both cases, a live DataObject is created first, then the Workflow is created.
Note. The
timeoutInSecondsparameter is provided as a tool for the user to optimize resource usage and manage costs. The value is used to terminate jobs that run longer than expected. Provide values greater than the default for anticipated long running jobs, or less for short jobs. The minimum time value is 60 seconds (1 minute).
Create an Import Sample Request
curl -L 'https://example.workbench.kingland-data-refinery.com/api/import' \
-F 'entityTypeID="1"' \
-F 'importType="live"' \
-F 'file=@"/data/import_records.jsonl"'
Sample request to import data directly to Workflows:
curl -L 'https://example.workbench.kingland-data-refinery.com/api/import' \
-F 'entityTypeID="1"' \
-F 'importType="live"' \
-F 'file=@"/data/import_records.jsonl"'
Sample request to import data to both DataObjects and Workflows:
curl -L 'https://example.workbench.kingland-data-refinery.com/api/import' \
-F 'workflowDefinitionID="1"' \
-F 'importType="live+workflow"' \
-F 'file=@"/data/import_records.xlsx"'
“Create an Import” Sample Response
The ID in the response is the ID required for checking the status of the asynchronous import job. The create import response is similar to the response from the GET /import API for getting the import status. Refer to the Get Import Status section for more information on all of the fields. Some fields are omitted for brevity.
{
"ID": 1,
"submittedTime": "2024-12-17T23:13:40.717521Z",
"startedTime": "0001-01-01T00:00:00Z",
"completionTime": "0001-01-01T00:00:00Z",
"status": 1,
"recordsProcessed": 0,
"recordsFailed": 0,
"importJobID": "e13f1349-65fe-4289-bf30-d111e6fe6e38",
"importFailures": null,
"stringStatus": "IN_PROGRESS"
}
Get Import Status via API
Once the import is created, the import job is queued for processing. If there is no queue, the import job will start quickly to upload the file. Depending on the size of the data being imported, it might take some time for the data import file to be ready for upload to Workbench. The import status retrieval API can be used to check the progress of the import process.
The Retrieve Import Status GET API submits a query request to retrieve the import status of the Import with the requested ID(no ID value retrieves the status of all imports). Additional information of failed imports can also be requested. Refer to the DR Workbench Get Import API for more information. Import status is retrieved on all of the most recent 50 imports. The following filters can be applied:
- The
IDquery parameter is the ID of the import job to check for status. This is not theimportJobIDstring in the create import response, but instead it’s the numericIDvalue. - The ‘status’ query parameter is the string status on which to filter.
- The ‘createdAt’ query parameter requests import status of imports submitted on or after the given date and time value.
- The ‘returnFailures=true’ query parameter requests additional import failure information that includes the record index and error message. Default is false. The record index is a particular record’s place in the import file, ordered from the start of the file (1st line starts at 1).
Get Import Status Sample Request
curl -X 'GET' \
'https://dev.workbench.kingland-data-refinery-dev.com/api/import?ID=1' \
-H 'accept: application/json
Get Import Status Sample Response
The import job will periodically update the status to notify that the job is still processing the Data Objects for import.
- StringStatus - IN_PROGRESS, SUCCESSFUL or FAILED. This is the status to look for.
- Status - numeric code corresponding to StringStatus field. 1 - IN_PROGRESS, 2 - SUCCESSFUL and 3 - FAILED.
- ImportJobID - Internal ID of the import job processing the request.
- submittedTime - Time when the import was requested.
- startedTime - Time when the import job started (after file upload).
- completionTime - Time when the import job completed.
- recordsProcessed - Number of data records processed from the input file.
- recordsFailed - Number of data records that failed to import.
- importFailures - List of data records that failed import with error messages and record index. Record index refers to a particular record’s place in the import file. This list is null unless requested with the ReturnValues argument of “true.”
Some fields are omitted for brevity.
[
{
"ID": 1,
"submittedTime": "2024-12-17T23:13:40.717521Z",
"startedTime": "0001-01-01T00:00:00Z",
"completionTime": "0001-01-01T00:00:04Z",
"status": 2,
"recordsProcessed": 50,
"recordsFailed": 0,
"importJobID": "e13f1349-65fe-4289-bf30-d111e6fe6e38",
"importFailures": null,
"stringStatus": "SUCCESSFUL"
}
]