Data Refinery Release Notes
Table of contents
- Data Refinery 1.9 Release (December 2025)
- Data Refinery 1.8 Release (August 2025)
- Data Refinery 1.7 Release (June 2025)
- Data Refinery 1.6 Release (March 2025)
- Features
- Data Refinery Designer - Background Task Query To Source Pattern
- Data Refinery Designer - Delete Previously Uploaded Source Data
- Data Refinery Designer - Background Task Monitoring for Email Notifications and Recent Task Executions API
- Data Refinery Designer - New External Source Template
- Data Refinery Workbench - User Interfaces for Data Import and Export
- Data Refinery - Dedicated Deployment Method
- Features
- Data Refinery 1.5 Release (December 2024)
- Features
- Data Refinery Designer - Permissions Framework for Background Tasks
- Data Refinery Designer - Prebuilt Background Tasks for External Sources
- Data Refinery Workbench - File-based Data Import using JSONL or Microsoft Excel
- Data Refinery Workbench - Exporting Data to Microsoft Excel Format
- Data Refinery Workbench - Custom Attribute Orders using Entity Type Definitions
- Data Refinery Designer - Add new Integration Framework with Data Refinery Workbench
- Minor Enhancements
- Defect Fixes
- Features
- Data Refinery 1.4 Release (August 2024)
- Features
- Data Refinery Workbench - Attribute Validation
- Data Refinery Workbench - Dropdown Support
- Data Refinery Workbench - Live Data Search
- Data Refinery Workbench - Export Data APIs
- Simplify Self-Hosted Deployment of Data Refinery Designer
- “Force” Delete a Project using the API
- Delete a Project with the UI
- Old Source UI Removed from Default View
- Defect Fixes
- Features
- Data Refinery 1.3 Release (June 2024)
- Data Refinery 1.2 Release (March 2024)
- Features
- Updated Data Refinery Logos
- Implement event-based Audit Logging for Project Changes
- Implement a new API for reading Audit Log events
- Preview Source Data in the New Projects UI
- Associate Users and Sources via the New Projects UI
- Edit Source Details and Project Details in the New Projects UI
- Update and Delete Users via the UI
- Introducing Data Refinery Trial Mode
- Data Query API Now Supports Source ID
- Defect Fixes
- Features
- Data Refinery 1.1 Release (January 2024)
- Data Refinery 1.0 Release (November 2023)
Data Refinery 1.9 Release (December 2025)
Data Refinery 1.9 released
Kingland is excited to announce the 1.9 release of Data Refinery, which adds better fine-grained support for document processing configurations and updates the default Anthropic model for document processing.
Read on to learn about all of Data Refinery’s excellent new features.
Features
Data Refinery Designer - Support for MaxOutputTokens and MixedContentProcessing Configurations
Documentation Sources now support two more configurations via the API. MaxOutputTokens controls the maximum number of LLM tokens that are used to process a document. This configuration allows a user to process larger documents while better controlling rate limits that are used to process a document. This configuration allows a user to process larger documents while better controlling rate limits hit by the upstream LLM Model Provider. MixedContentProcessing was previously enabled by default in Data Refinery 1.8, but can now be controlled at a granular per-Source level instead of being permanently enabled. This allows users to control their costs more efficiently by only enabling MixedContentProcessing on Sources where the uploaded files contain both text and image assets that should be used during extraction.
To get started with the new configurations, read more here: Advanced Documentation Source Configuration
Update Foundation Model for Anthropic to Claude Sonnet 4.5
This release changes the underlying Foundation Model used when running AWS Bedrock or direct Anthropic integrations to use Claude 4.5 Sonnet instead of Claude 4.0 Sonnet. System Prompts have been updated to take advantage of this new model, resulting in slight improvements in the quality of output from Documentation Sources when using the new Anthropic Foundational Model.
No changes are required to take advantage of the new Foundational Model, all Documentation Sources will use the new model automatically when the system is configured to use AWS Bedrock or direct Anthropic integrations.
Minor Enhancements
- This release adds client-side caching to the Data Refinery Designer user interface.
- Improved Documentation Source Performance when the system is under heavy load
- Added Streaming Source API documentation to the OpenAPI documentation
- When uploading documents to a Documentation Source, the initial name of the document is now included in the output attributes table for easier document matching after attributes are extracted.
Bug Fixes
- Fixed an issue where the AI Processor may fail to persist an attribute from a document when the system is under heavy load
- Fixed an issue where users could attempt to upload a document to a Documentation Source that was failing validation
- Fixed an issue where users needed to be a PROJECT_ADMIN on some Sources to add target attributes
- Fixed an issue where Documentation Sources with large extracted outputs caused display issues with the Sample Data table
- Fixed an issue where Streaming Data Sources showed the “Upload Data” button
Data Refinery 1.8 Release (August 2025)
Data Refinery 1.8 released
Kingland is excited to announce the 1.8 release of Data Refinery, which introduces significant enhancements to Documentation Sources to allow scanning images, brings support for custom AI models, and adds a new streaming source type for streaming record data to Data Refinery.
Read on to learn about all of Data Refinery’s excellent new features.
Features
Data Refinery Designer - Documentation Source User Experience Enhancements
Documentation Sources now include enhanced API capabilities and improved user experience features. Users can now preview data in Documentation Sources and query it using the Source query API, providing better visibility into processed document data before it’s used in analytics workflows. Additionally, the UI now supports editing additional prompt context, allowing users to fine-tune how AI processes their documents for more accurate data extraction. Users can now also collapse the Source details that load on the top of the page, so they can use more screen space for viewing details about their data or editing their prompt context.
Data Refinery Designer - Bring Your Own Model to Document Processing
Data Refinery Designer now supports bringing custom API keys for AI model usage in document processing. Users can configure their own Anthropic Claude or OpenAI ChatGPT API keys, providing more flexibility and control over AI processing costs, and allowing customers to use pre-existing agreements with AI processing vendors. Only one AI model can be used per refinery installation, ensuring consistent document processing across all Sources.
A new configurations UI has been added that requires the CONFIG_ADMIN permission, allowing administrators to switch between AI models and manage API keys securely. All API keys are encrypted at rest when stored in the database, maintaining security best practices for sensitive credentials.
Data Refinery uses Anthropic’s Claude through AWS Bedrock to tune prompts. While we try to ensure a minimum baseline of performance between models, users who use ChatGPT may need to provide more context in their Sources compared to users who use AWS Bedrock or Anthropic Claude
Data Refinery Designer - Documentation Sources Support Image Processing
Documentation Sources can now process well-known image formats including .gif, .jpg, .webp, and .png files. This expands the types of unstructured data that can be processed by Data Refinery, allowing for use-cases such as reading family trees or graphs. When uploading image files to Documentation Sources, the AI will extract data from the images based on the configured prompt context. Additional prompt context is required to effectively parse images, as the LLM will typically need context about what data is being extracted from the document and how it should interpret the images.
Data Refinery Designer - Add a New “Streaming” Source Type
A new “Streaming” Source type has been added to support near-real-time data ingestion scenarios. This Source type allows users to send records one at a time without causing major performance issues by staging records for a configurable amount of time before writing them to the Source. After the configurable time has passed, all staged records are batched together and automatically inserted into the most recent version of the Source. All Streaming Sources use the Parquet Source classification to ensure optimal query performance and costs. Records can be sent as an arbitrary flat JSON object, and the schema of the Source will be automatically inferred the first time a batch of records is added to the Source.
Streaming Sources support the use of Versions to differentiate data, support the use of the query APIs to query the data in the Source, and inherit the same great role based permission scheme as other Sources in Data Refinery.
Minor Enhancements
- UI Themes have been tweaked to remove background images and slightly update the color palette
- Users with the
USER_ADMINpermission can now use the APIs to explicitly lock and unlock users - Background Task Environment Variables may now be edited in the UI instead of requiring API access
- Background Task Command strings may now be edited in the UI instead of requiring API access
- “DocumentToken” cost factors are now available via the API to help organizations determine how much processing a given document costs.
Data Refinery 1.7 Release (June 2025)
Data Refinery 1.7 released
Kingland is excited to announce the 1.7 release of Data Refinery, which adds support for using Artificial Intelligence to parse unstructured data from documents. In addition, the experience for Operations teams that use Background Tasks has been improved to assist with troubleshooting failing Background Tasks.
Read on to learn about all of Data Refinery’s excellent new features.
Features
Data Refinery Designer - Add a new Artificial Intelligence Documentation Source Type
When creating a new Source in Data Refinery Designer, users can now select “Documentation” as a new option for Source Type. Documentation Sources behave differently from the other Source types; instead of uploading structured data to a source then combining it with other Sources, users will instead upload unstructured text documents to Documentation Sources. These unstructured documents are read by Artificial Intelligence to extract attributes from the document, which are then stored in the same Warehouse Database as data from other Sources. The data uses the same permissions capabilities as the rest of Data Refinery Designer, allowing administrators to lock down permissions on individual Sources.
Documentation Sources includes full UI support for viewing the status of documents, along with defining metadata about the document processing pipelines, such as names and definitions of what attributes are being extracted for different sources. The Sample Data page will be updated to support Documentation Sources in an upcoming release.
To get started with a Documentation source, read more here: Getting Started With Documentation Sources
Data Refinery Designer - View Background Task Executions
With a previous release of Data Refinery Designer, a feature was added that allowed the user who owns a Background Task to receive an email when that Background Task execution failed. Background Task executions have been available via the APIs since the initial release of Data Refinery, but haven’t had a UI exposed that allowed a more user friendly experience. With 1.7, users can now view information within the UI about the past 50 times that a Background Task has executed. This will provide information to the user such as the unique task identifier, the Success or Failure status of the task execution, the time the Task finished, and an integer-based exit code. This information can be used by system administrators to provide more detailed information (such as logs) to users, if needed to help troubleshoot tasks. It also allows users to know about the status of tasks without needing to use the API.
Improved Security Features
Data Refinery Designer now includes 2 new security features: Rate Limits and User Locking. Data Refinery Designer now includes a default rate limit that is split between Unauthenticated APIs and Authenticated APIs. When a single user or IP address makes too many requests, the rate limit will return a HTTP 429 response, along with information on when the rate limit will reset to allow the user to try again. With User Locking, users who fail to authenticate too many times will have their account locked for 15 minutes.
These two security features improve the security posture of Data Refinery Designer in cases where the application is under attack, and ensure that user accounts and data remain as secure as possible. Rate limits may be configured in cases where customers want a higher value, but User Locking is not configurable and will always be enabled.
Minor Enhancements
- When creating a new version of an existing External Source, the new version will be available for query in near-real time instead of requiring a waiting period to be recognized by the system. Schema changes to the External Source will still require the waiting period to be recognized.
- Username is now case insensitive both when logging in, and when using forgot password
- Various pages on the UI now have tooltips that direct the user to documentation corresponding to the feature for help
- Using the
RunTaskAPI to start a new background task execution will no longer require the user to know what the Background Task image is for a Query To Source task. The image will be automatically updated by the API.
Data Refinery 1.6 Release (March 2025)
Data Refinery 1.6 released
Kingland is excited to announce the 1.6 release of Data Refinery, which adds several new features and enhancements to improve data management, deployment efficiency, and user experience.
Data Refinery Designer introduces a new feature, the Query To Source background task pattern, allowing users to automate data analysis tasks with minimal inputs and reducing the need for development resources. Designer also gains the ability to delete previously uploaded Source data. Further, Designer now sends Email notifications for task failures, provides a new API to obtain task execution result status, and adds a new external Source template.
Data Refinery Workbench gains user interfaces for Data Import and Export along with email notifications for completed Import and Export tasks.
Data Refinery now provides the Dedicated Deployment Method that streamlines the deployment and upgrade process, reducing IT workload and ensuring up-to-date software.
Read on to learn about all of Data Refinery’s excellent new features.
Features
Data Refinery Designer - Background Task Query To Source Pattern
This feature introduces a new type of Background Job Pattern that can be used to create Background Tasks easily: the “Query To Source” background job. Using this pattern, a Data Engineer can create a Background Task without needing to create a new container image, and with only four inputs:
- SQL Query to run
- Source in which to upload the resulting dataset
- Boolean true/false whether the new dataset should create a new version
- Cron schedule for how often it runs
The “Query To Source” pattern enables data engineers to automate data analysis and filtering tasks, reducing the need to create containers for routine data operations and increasing operational efficiency and scalability. When the Background Task runs, it will use the permissions of the Owner user to execute a query using the given SQL, then it will upload the results of that query to the specified Source.
When creating a new Background Task, a dropdown containing either “Query To Source” or “Custom” allows Data Engineers to choose what type of Background Task they’re creating, allowing them to use the new pattern without needing to call the API.
Data Refinery Designer - Delete Previously Uploaded Source Data
When reviewing data uploaded to a Source, it’s possible to discover data that is either invalid or duplicated. Previously, there was no way to correct this without discarding the entire Source Version. In this release, users with either PROJECT_ADMIN permission or an Owner Project Role can delete individual data files from a Source to ensure the data remains clean. Uploaded data can be deleted within a Source Version entirely or by individual file paths.
As part of this improvement and to help prevent duplicate data, files are now stored using a hash of their contents which allows the system to identify and prevent duplicate uploads.
Data Refinery Designer - Background Task Monitoring for Email Notifications and Recent Task Executions API
The Background Task scheduler has been updated to send email notifications to the task owner in case of task failures. This includes failures to start or complete the task. This ensures that task owners are promptly informed of any issues, allowing for quicker resolution and improved reliability.
As part of this improvement, a new Recent Task Executions API is added. The new GET /api/tasks/{task_id}/executions API retrieves information on up to 50 of the most recent executions of a task. A Task Execution provides the task identifier, completion time, and exit code of an executed task. No special permissions are required to access this information, but users must be authenticated.
Data Refinery Designer - New External Source Template
We continue to expand the capabilities of Data Refinery Designer by adding support for a new external template source, NCCS Charities:
- National Center for Charitable Statistics (NCCS)
501(c)3 Charities, Scope 'PZ'data
As with previous external sources, all files are translated to Parquet or JSONL data formats before being uploaded into Data Refinery, optimizing performance for queries and reducing costs for users.
Data Refinery Workbench - User Interfaces for Data Import and Export
This release includes new user interfaces for importing and exporting data within Data Refinery Workbench. Users can now easily manage their data imports and exports through dedicated pages, enhancing their overall experience and efficiency.
- Data Export Page: A new Data Export page allows users to view and download their exports.
- Data Import Page: A new Data Import page lets users start new imports and view the status of existing imports.
- Export Button in Search UI: A new export button in the DR Workbench Live Data Search UI enables users to create exports based on current search results.
- Email Notifications: Users now receive email notifications when their imports or exports complete, with links to download the files or view additional status information.
Data Refinery - Dedicated Deployment Method
This release introduces a significant update to the deployment method for Data Refinery Designer, transitioning from a self-deployed model to a dedicated deployment model. This change aims to streamline the deployment and upgrade process for customers, reducing the time and effort required from their IT departments and minimizing friction between business and IT teams.
As a customer IT lead, minimizing the time spent on deploying and upgrading Data Refinery is crucial. The dedicated deployment method addresses this need by shifting the responsibility of deployment and upgrades to Kingland. Customers will provide an AWS account, and Kingland will handle the deployment, upgrades, and managed services, ensuring that customers stay up-to-date with minimal effort.
Data Refinery 1.5 Release (December 2024)
Data Refinery 1.5 released
Kingland is excited to announce the 1.5 release of Data Refinery, which adds several public data source templates to Data Refinery Designer along with a detailed permissions framework for Background Tasks. Data Refinery Designer gains the ability to import and export data using Microsoft Excel, and Data Refinery Workbench gains the ability to specify the display order of Entity Attributes.
Read on to learn about all of Data Refinery’s excellent new features.
Features
Data Refinery Designer - Permissions Framework for Background Tasks
When running Background Tasks in Data Refinery Designer, Tasks will typically need to perform an action then re-upload data to Designer. These Tasks include running analytics queries, downloading files, or extracting data from an upstream source system. Prior to this release, to access Designer APIs, users would need to include a username and password in the environment variables of the Task definition, which could cause problems when passwords rotate or users are deactivated.
Background Tasks are now associated to a single “Owner” user, and any user with the new TASK_EDITOR permission can take ownership of Tasks if they are not the current owner of the Task. A user must own a Task to edit the Task, ensuring that a user cannot make a change to a Task and run it on behalf of a separate user.
Since a Background Task now has an Owner, Tasks inject a set of access tokens into each Background Task when it runs, allowing the Task to authenticate to the APIs as the owner User, with the same permissions to Projects and Sources as the owner User.
Data Refinery Designer - Prebuilt Background Tasks for External Sources
It’s common for analytics jobs to include comparing data from publicly available sources that are considered authoritative. To ensure that users of Data Refinery Designer can get analytics jobs up and running as quickly as possible, this release introduces several pre-built Background Tasks that will retrieve data from key public sources and automatically upload that data into new Source Versions within Data Refinery. With Data Refinery 1.5, this includes the following public data sources:
- Federal Deposit Insurance Company (FDIC)
InstitutionsdataLocationsdata
- Federal Financial Institutions Examination Council (FFIEC)
Attributes ActivedataAttribute CloseddataAttributes BranchesdataRelationshipsdataTransformationsdata
- Investment Advisor Public Disclosure (IAPD)
SEC Investment AdvisorsdataState Investment AdvisorsdataInvestment Advisor Representative Reportdata
All files are translated to Parquet or JSONL data before being uploaded into Data Refinery to ensure optimal performance for queries and lower cost for users of the Prebuilt Background Tasks.
Look for more pre-built Background Tasks in upcoming releases of Data Refinery Designer!
Data Refinery Workbench - File-based Data Import using JSONL or Microsoft Excel
When users want to make bulk changes in Data Refinery Workbench, they could create multiple workflows and take advantage of Workflow Definitions, but it can sometimes be more efficient to output the data, make changes in bulk in the file, then re-import the file. Previously, users would need to make API calls for each row of their file; with this release users can upload files to a new import API in Workbench, and Workbench will import the file directly into an Entity Type and/or Workflow Definition.
Users can import data into the Live Data, a Workflow, or both the Live Data and a Workflow.
Data Refinery Workbench - Exporting Data to Microsoft Excel Format
In addition to the ability to import files, the Export APIs for Data Refinery Workbench have been updated to include a new File Type argument that allows exporting data in either the previous JSONL format or the new Microsoft Excel format. Exporting data to Microsoft Excel provides an additional option for manipulating data in Data Refinery Workbench, and can further assist with making bulk changes to data.
Exporting to Microsoft Excel is limited to 2 GiB of data, while exporting to JSONL supports up to 50 GiB of data, making JSONL more efficient for system-to-system integrations while Excel may be more user-friendly when a user plans to open and manipulate the exported file.
Data Refinery Workbench - Custom Attribute Orders using Entity Type Definitions
When attributes were displayed on the user interface, certain attributes often want to be grouped together. Previously, attributes sorted alphabetically which made this difficult and sometimes required odd naming conventions to ensure attributes grouped in the way users wanted. Now, a new Display Order field can be included on every attribute defined for an entity. The Live Data Search list and Details pages, and the Workflow list and Edit Workflow pages on Data Refinery Workbench will now sort attributes based on the order defined within the Display Order field, which allows users to sort attributes on the respective UI pages regardless of naming conventions.
Attributes with no defined Display Order will display below attributes with a defined Display Order. When two or more attributes have the same Display Order, they will continue to sort alphabetically.
Data Refinery Designer - Add new Integration Framework with Data Refinery Workbench
Data Refinery Designer can now establish a new Integration between Designer and Workbench. This Integration allows Designer to make API calls to one or more Workbench instances on behalf of users who have scheduled jobs in Designer. Integrations can be configured with the current release, with additional functionality coming that will make use of the Integration in the next release.
Minor Enhancements
- Icons are now included on menu items in Data Refinery Designer, aligning the navigation experience with Data Refinery Workbench and providing more visual clarity for the navigation bar.
- Data Refinery Designer now allows updating the comment associated to a Source Version, allowing users to correct typos or include additional information later if desired.
- User Administration on Workbench and Designer now uses updated pagination and sorting and stores the current status in the URL. This improves performance dramatically in deployments with a large number of users. This new functionality is also used when managing group membership, improving performance when managing groups with many users.
Defect Fixes
- Workbench: Fixed an issue where creating or updating dropdowns used a different API Key than the read operation returned
- Fixed an issue with Entity Type, Group, and Definition APIs accepting values that were whitespace only, had leading whitespace, or had trailing whitespace.
- Fixed an issue with the Data APIs that caused errors when attributes newly added to an Entity Type were added to a historical data object.
- Fixed an issue where Workflows with no name couldn’t be clicked on in the UI. Workflows with no name defined will now generate one using the Key attributes of the data when created.
Data Refinery 1.4 Release (August 2024)
Data Refinery 1.4 released
Kingland is excited to announce the 1.4 release of Data Refinery, which moves Data Refinery Workbench out of beta, along with adding several new features to Data Refinery Workbench! In addition to releasing Data Refinery Workbench, Data Refinery Designer has a simplified deployment process to make self-hosting the Designer easier!
Read on to learn about all of Data Refinery’s excellent new features.
Features
Data Refinery Workbench - Attribute Validation
In order to ensure that data is accurate, a DEFINITION_ADMIN can now specify validations that apply to individual attributes within an Entity Type. This allows administrators to specify a minimum viable quality that must be met for changes to be made to a record. However, not every operation performed on a record requires validation. For example, an admin may not want to require validation to create a new record, since the point of creating the record in Workbench is to improve the quality. As a result, several new flags are available on Entity Types and Workflow Definitions that help control when validation is required as opposed to optional.
Validations can be configured on individual attributes using Regular Expressions, and several examples of common validations are provided in the new Attribute Validation documentation.
Data Refinery Workbench - Dropdown Support
Some data attributes are best expressed as a list of possible values that an end user can choose from, such as address data to select states or provinces. With this release, Data Refinery Workbench now supports creating new Dropdowns which can then be associated to attributes as part of an Entity Type. When a Dropdown is associated to an Entity Type Attribute, Workbench will automatically validate that the value a user selects is present in the Dropdown list, regardless of whether the value is updated via the UI or the API.
A Dropdown may have up to 1,000 individual values added to it. A single Dropdown may be associated to many different Entity Type Attributes, and may be associated to more than one Entity Type.
Data Refinery Workbench - Live Data Search
Users may now search for Live Data in Workbench, allowing a user to view the authoritative version of the data at any time. Users may perform a search with up to five different Attribute and Value combinations within the Entity Type, which will return any record that matches all the criteria. Clicking on a record in the search will display all the attribute values for that record, and allows a user with the WORKFLOW_ADMIN to instantly create a new workflow for that record from the UI. Users may also copy the URL of searches and bookmark them or share them with other users to view!
Data Refinery Workbench - Export Data APIs
Workbench now supports exporting up to 50GiB of data at once using an export API. This allows users to export data from the Live Data into a JSONL file, which can be imported into Data Refinery Designer to help perform further analysis of the data. Up to three unique Attribute and Value combinations can be used along with an Entity Type to filter what data should be included in the export.
Once an export is started, it will run automatically in the background and be available when the status has changed to COMPLETED. A full example of how to create and download an export is provided in the new export documentation! A User Interface for exports will be provided in a future release.
Simplify Self-Hosted Deployment of Data Refinery Designer
Previously, deployment of Data Refinery Designer required a three step process to deploy infrastructure for containers, deploy the containers, and finally deploy the remaining infrastructure. This would have caused confusion with customers who had IT departments not used to working with private containers. With the 1.4 release, the Data Refinery Designer deployment process no longer requires this three step process, and will instead automatically create the container infrastructure on first deployment. This makes it significantly easier for customers to deploy and upgrade Data Refinery Designer.
Updated deployment instructions without the initial two steps are available now in the Deployment Instructions documentation. Older versions of Data Refinery can be upgraded to the new version seamlessly, and require no manual effort to replace the pre-existing container infrastructure.
“Force” Delete a Project using the API
Previously, when a user with PROJECT_ADMIN wanted to delete a Project, users would need to potentially take multiple steps to ensure that the Project was cleaned up prior to deleting it, otherwise the API would return an error. This prevented Sources from becoming orphaned without Project association, and ensured that permissions for users were updated properly before the Project was removed. It also ensured that a user explicitly intended to delete the Project and didn’t accidentally push a button or issue the wrong API call.
With this version of Data Refinery, a new force=true parameter has been added to the API for deleting projects. When this parameter is included, the API will handle automatically removing all Source associations and updating Permissions behind the scenes.
Delete a Project with the UI
With the new force setting added to the API, the UI now also supports the ability to delete a Project. A user with PROJECT_ADMIN will now see a new Delete Project button on the UI, which will warn them that the action will remove the Project in addition to the associated Sources and User Project Roles. After the user confirms the action, the Project will be deleted along with any User and Source associations.
Note. This action may take some time if the Project has a significant number of Sources or Users. During the deletion process, the Project will still be viewable until deletion has completed.
Old Source UI Removed from Default View
As mentioned in the prior release of Data Refinery, the new Source experience that’s on the Project UI is now at feature parity with the old Source UI. To prevent confusion about which UI should be used, the old Source UI now requires PROJECT_ADMIN global permissions to view, which will hide it from view for most users. The new Project UI is now the default view for all users when they first login.
Defect Fixes
- Fixed an issue where selecting a different page size on the Data Refinery Workbench Workflow UI wouldn’t apply the new page size properly.
- Fixed an issue where Data Refinery Designer could fail to remove Source data targets properly if multiple people attempted to remove the same Source data at the same time, which could cause a failure in the underlying infrastructure that was difficult to resolve.
- Fixed multiple UI overlaps and issues where tooltips weren’t properly visible.
Data Refinery 1.3 Release (June 2024)
Data Refinery 1.3 released
Kingland is excited to announce the 1.3 release of Data Refinery, which introduces a brand new component of the Data Refinery Platform as a Beta release: Data Refinery Workbench! Data Refinery Workbench allows users to run a Data Management operation in a simple and flexible manner with the same data-first approach that Data Refinery uses. All an administrator needs to do is specify their Data Schema and Workflow Steps to be ready to go! View more information in the Data Refinery documentation by reading the Data Refinery Workbench page.
In addition to the new Workbench component, the 1.3 release also makes some great changes to Data Refinery by ensuring easier Source management, adding APIs for retrieving Audit Logs, and improving the UI experience of the Projects page.
Read on to learn about all of Data Refinery’s excellent new features.
Features
Data Refinery Workbench Beta
A new Beta for Data Refinery Workbench is available. The Beta is fully tested, and the released features are ready for use, however some features that customers may want to use for Data Management are not yet available. Data Refinery Workbench uses a separate set of users from Data Refinery, allowing permissions to be assigned to either application individually. Available features include creating Entity Definitions, creating Workflow Definitions, creating User Groups, and staging changes to Entities.
Create Entity Definitions
A key part of managing data is the ability to ensure that data conforms to a certain schema. With this release, a user with the DEFINITION_ADMIN permission can create new Entity Definitions and add Attributes to them. Once created, Attributes show up in the UI when editing and viewing entities automatically. See Entity Type Definitions Documentation for more information!
Create Workflow Definitions
Most Data Management programs require a separation of duties for users who can edit data as opposed to users who can review data. Data Refinery Workbench supports creating Workflow Definitions, which allows a user with the DEFINITION_ADMIN permission to design a business process flow. This flow can have multiple states and transitions to assign users to individual transitions. Assigning users to a transition ensures that only users who have the proper permissions can move entities through the workflow, ensuring a clean separation of responsibilities. For more details, see the Workflow Definition Documentation.
Create User Groups
When assigning Users to Workflow Transitions, it’s likely that more than one user should be assigned to a transition. Instead of requiring an admin to assign many individual users to a single transition, Data Refinery Workbench supports User Groups, allowing users to be grouped together prior to being assigned to a transition. This allows users with the USER_ADMIN permission to group many users together then share that group with a DEFINITION_ADMIN user, creating a clean separation of responsibilities even at a system administration level.
Stage Changes to Entities
As Entities are being changed through a workflow, the data changes being proposed should not impact data quality until the changes have been approved. Data Refinery Workbench allows users to make as many changes within a workflow as they would like, and changes are not completely saved to the live data store until a workflow has been approved.
Updates to the Source Experience on the new Projects UI
With this release, the Projects UI has received several updates, and will shortly become the default experience for users who log in. These improvements mean that the only reason a user would currently need to navigate to the old Sources page would be to delete a Source. The updates include:
- Users can now create new Source Versions by clicking on a Source, then selecting “Create Version” under the Versions tab
- Users can now upload new data to a Source Version by clicking on a Source, then selecting “Upload Dataset” under the Versions tab
Expect the Sources page to be hidden for most users in the next release!
Source Data Type Validation
Previously, users could upload mixed data types to the same Source and accidentally break a Source’s ability to read new data. For example, a user who uploaded a CSV file one day, and subsequently uploaded a JSONL file could break a Source. Sources now require a Classification when created and updated. This will validate any new data uploads to ensure they match the new Classification.
For Sources created before version 1.3, the Classification field will remain blank, but will be required on the next update. Data uploaded to a Source with no Classification will not be validated. The Classification is now present in the Source details view on the new Project UI, so users know what data format should be used to upload new data.
This helps prevent issues with Sources when multiple people are uploading data sets.
Easier Source Creation
Up until now, creating a Source has required that a user have the PROJECT_ADMIN or PROJECT_CREATOR permission, because it required the ability to see all Sources within the system. This limited the ability to create Sources to a minimal number of people within the system, and could make it difficult for an Analyst level user on a Project to create a Source that they wanted to perform further validation on.
With 1.3, users can now input a project_id when creating a Source via the API, and the Source will be immediately associated to the input Project when it’s created. Since this fixes the issue where users needed to be able to see all Sources to associate the Source to a Project, Analyst and Owner User Project Roles can now create Sources, but only if the created Source is associated to a Project they have a User Project Role on.
This helps simplify Source creation, and allows users who are analyzing data on a Project to be able to store transient data states without needing to contact an admin!
Source Renaming
Source Data in Data Refinery is stored in an extremely scalable and flexible fashion to allow a significant amount of data to be uploaded to Data Refinery without causing system instability. However, this caused issues in the past when Sources were renamed, because the Source would lose reference to data that was uploaded under an old name.
With this release, Data Refinery now stores that context separately from the Source Name, allowing users with an appropriate Permission or User Project Role to rename a Source. In addition, Data Refinery now supports a larger set of characters when creating Source Names, allowing the use of things like spaces in Project Names. When a Source Name is changed, Data Refinery will cascade that change into the Warehouse Database to ensure that users don’t get confused.
Note. If there are operational queries that run on those Sources through a BI tool, the queries in the BI tool may fail after changing a Source Name. Make sure all appropriate queries are updated after changing a Source Name!
New Audit Log API Allows Retrieving Audit Logs
In Data Refinery 1.2, support was added for storing audit logs related to Projects, Project Source Associations, and more. While those logs were stored, there wasn’t a convenient way to retrieve the data in a way that it could be inspected. Now, a user with the AUDIT_READALL permission is able to call a new API to retrieve the log data by calling a new API. The API supports filtering on event name, Project, Source, timeframe, and the user who triggered the event. This can help a team who is attempting to identify a change determine exactly what happened without having to sort through every event within the system.
Data Refinery 1.2 Release (March 2024)
Data Refinery 1.2 released
Kingland is excited to announce the 1.2 release of Data Refinery, which greatly simplifies managing Project associations to Users and Sources by adding a UI to manage associations. Moreover, this release increases the security of the system by capturing audit events for actions taken by users.
Read on to learn about all of Data Refinery’s excellent new features.
Features
Updated Data Refinery Logos
Previous Data Refinery releases used the Kingland Logo for browser tab icons, and “Kingland Data Refinery” as the product name, all spelled out. With 1.3, the Kingland logo has been replaced with the specific product logo for Data Refinery, and the product name is now just “Data Refinery” throughout the application. This change affects both the Data Refinery Designer UI along with the associated user documentation.
Implement event-based Audit Logging for Project Changes
Data Refinery will now capture and record audit logs, along with snapshots of Project metadata, when changes are made to Projects. The following Project related events are now tracked:
- CreateProject is logged when a new Project is created.
- UpdateProject is logged when a Project’s Name, Description, or Type is updated.
- DeleteProject is logged when a Project is deleted.
- AssignUPR is logged when a user is assigned as either an “Analyst” or “Owner” role on a Project.
- RemoveUPR is logged when a user’s role is removed on a Project.
- AssociateSource is logged when a Source is associated with a Project.
- DisassociateSource is logged when a Source is removed from a Project.
See Audit Logging for more details!
Implement a new API for reading Audit Log events
Data Refinery now exposes a new GET API to retrieve Audit Log Events, and a new AUDIT_READALL permission has been introduced to control which users have access to read the audit logs. All requests to the Audit Log API are subject to a permissions check. The API allows users to filter based on Event Name, Source ID, Project ID, Event Time, the UserID of the user who triggered the event, or any combination of those attributes.
Users with the AUDIT_READALL permission are able to see all Audit Logs in the system, even if they do not have permissions to see Projects or Sources. However, even if a user does not have the new AUDIT_READALL permission, they can still read Audit Logs for Projects where they have an Owner role on the Project.
See Swagger Documentation for more details!
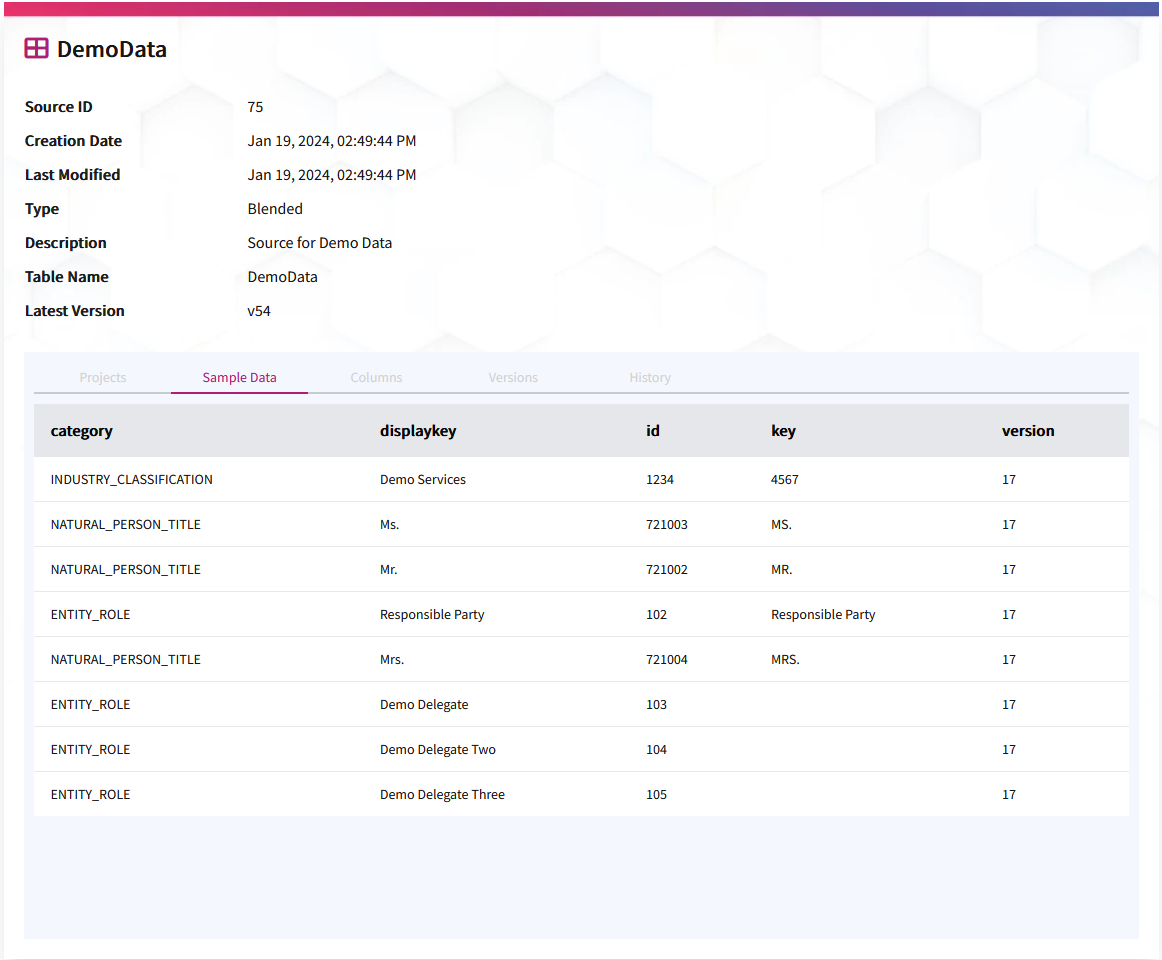
Preview Source Data in the New Projects UI
When viewing Projects in the new Projects Layout, all the associated Sources are also shown in a dropdown to the left of the screen. When selecting a Source to view additional details, the first 10 rows of data from that Source will now be shown in the UI as a preview of what data is available within the Source. As always, a user must have a valid Analyst or Owner Project role to view the data preview.
Associate Users and Sources via the New Projects UI
Previously, associating Sources to a Project or assigning Users to a Project required the use of the API. Both of these functions are now available via the UI. A user with the proper permissions can easily manage access and data within their Projects.
Edit Source Details and Project Details in the New Projects UI
Source details in the Projects UI has been view-only since it was introduced, with changes to Source details requiring the use of the Source page. With this release, Source details may now be edited in the new Project UI, allowing users to make changes without needing to navigate away from the page or open a second tab.
Update and Delete Users via the UI
Data Refinery 1.1 introduced the View and Create User functionality via the UI. Data Refinery 1.2 has further expanded this page to allow users to update or delete users. This allows a user with the proper USER_ADMIN permission to update a User’s Email, a User’s Global Permissions, or delete a user as needed.
In addition, when a user without proper permissions previously navigated to this page, they would receive a JSON-formatted permissions error. Now, a proper HTML-formatted error page is displayed when a user navigates to a page they do not have permissions to view.
Introducing Data Refinery Trial Mode
With this release, a License from Kingland is now required to run Data Refinery. This license is validated against a license server each time the product is deployed, scales up, or at a periodic interval when running. Metrics of Sources and Projects are sent to the license server, but Source data is never sent to the license server.
When no license is installed, Data Refinery will run in Trial Mode, which will limit the number of Users, Projects, and Sources that can be created. The amounts of data that can be uploaded in a single file is also restricted. The restrictions are:
- 5 Sources
- 5 Projects
- 10 Users
- 1MB of data uploaded at once
If you have questions regarding Trial Mode or want to obtain a license to remove restrictions, please contact your Kingland Customer Support Representative!
Data Query API Now Supports Source ID
The API now accepts Source ID in addition to Source Name to query in situations where the Source Name is ambiguous. Source Names in Data Refinery are not unique as multiple Sources could have the same name. Previously, querying the data API required a Source Name for ease of use, but this could lead to rare issues where the Source Name wasn’t unique, leading to errors. Now, either Source Name, Source ID, or a mixture of both may be provided to the API for querying data.
Defect Fixes
- Fixed an issue where a Project that had a user with multiple Project Roles assigned could appear in the GET API multiple times.
- Fixed an issue where attempting to upload data to a non-existent Source could eventually cause the API server to restart.
- Fixed an issue where a system admin manually manipulating database roles within the Warehouse Database could cause permission errors when Users are associated to Projects.
- Greatly increased the number of User and Project associations allowed before a user experienced permission errors. A user may now be associated to more than 1,000 Projects, and a Project may now have more than 1,000 Users associated.
Data Refinery 1.1 Release (January 2024)
Data Refinery 1.1 released
Kingland is excited to announce the 1.1 release of Data Refinery, which introduces new user interfaces (UIs) for viewing Projects and Users. Additionally, this release enhances system security by allowing tokens to have shorter lifespans, adds support for sending emails, and adds support for trial deployments.
Read on to learn about all of Data Refinery’s excellent new features.
Features
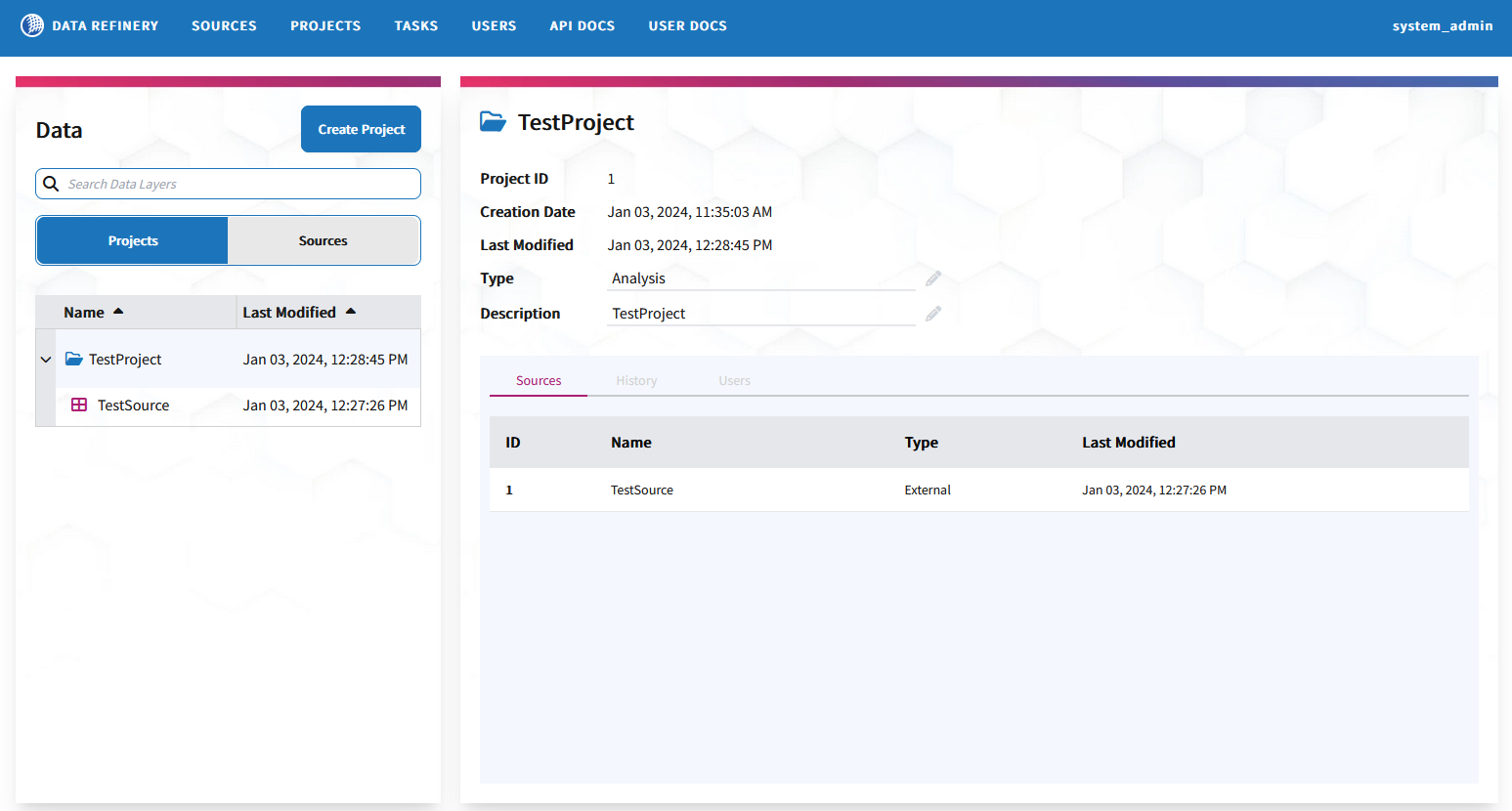
Introducing the New Projects UI
A new Project interface has been created that centralized a significant amount of information about a [Project] (/docs/#projects), starting with the Project and Source relationships. This UI is now the default landing page for Data Refinery after a user has logged in. This allows the user to see both Projects and Sources together in a single view, along with making the relationships between them easier to understand.
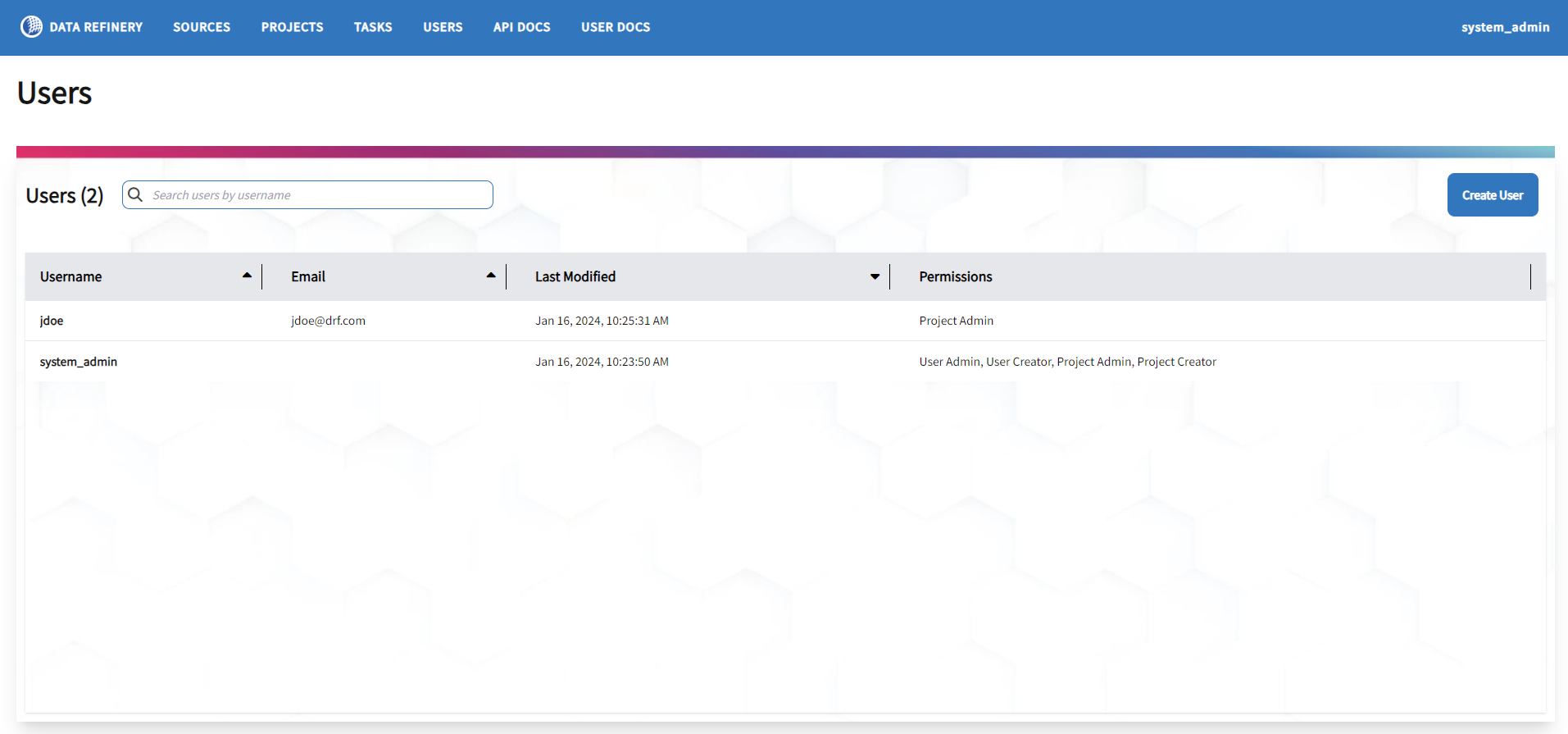
Introducing the Users UI
A new User interface has been added that allows a user with USER_ADMIN or USER_CREATOR permissions to view users who are provisioned within the system and their permissions. This release also introduces the first piece of functionality for this page, which is the ability to create a new user directly within Data Refinery. Previously, this required the use of the API or an external Identity Provider configured to use OpenID Connect (OIDC).
Added Support for Sorting and Filtering in the sources/query API
This release expands querying support within the sources/query API that allows a user with proper permissions to access Source data via the API. Users can now specify sorting options and query options to the API, which will allow for more refined query capability. The API is still limited to returning 1,000 results to ensure a performant API request. Visit the API Documentation for more details.
Added API Support for Manually Managed Source Schemas
When creating a Source normally, the schema for the Source is inferred by the data that is uploaded to the Source. It’s not possible to remove a column when inferring the schema, and it’s not possible to specify the column data type. Manually Managed Source Schemas allow a user to specify the schema for a Source without inferring the schema from a data file. This allows a user to delete columns, define data types, and rename columns.
This functionality allows a Project Administrator to provide significantly more information to a data engineer or analyst working with the data around the contents of the Source. In addition, it allows a Project Administrator to define the format of a Source without needing to first upload data. Manually Managed Sources are removed from the schema inference process, which also reduces cost. Visit the API Documentation for more details.
Added Refresh Token Support
Data Refinery uses OAuth bearer tokens for authorization when calling the API, however long-lived bearer tokens can cause security issues if compromised because they are not easily revoked. For this reason, the lifetime of a bearer token in Data Refinery has defaulted to a shorter session time, which can cause frustration for end users who need to frequently re-authenticate.
With Data Refinery 1.1, the system will now issue a long-lived refresh token that is explicitly revoked on logout, and the refresh token can now be used to retrieve a short-lived bearer token for use with the API. This allows system administrators to configure a much longer session lifetime for a user without sacrificing system security.
The duration of the bearer token and the refresh token are both configurable, so a system administrator can decide their own security posture based on the data within the system.
Added the Data Refinery License Service
Data Refinery License Server is a new Data Refinery component hosted by Kingland, and allows the Kingland support team to issue licenses for Data Refinery. An installed license will be validated every 24 hours, or when the system load increases. Data Refinery will let users exceed their license limits to ensure that business critical problems are not blocked.
Added Email Support
Data Refinery now has the ability to send plain text emails using Amazon Simple Email Service (SES). Once a domain has been validated in SES, emails can be delivered to any Data Refinery user configured with an email. Data Refinery will now deliver emails for Forgot Password requests, allowing users to completely self-service password reset. Simple Mail Transfer Protocol (SMTP) email is not currently supported. In addition, Data Refinery allows for a configurable email regex that specifies which addresses can receive emails.
This functionality allows users to be completely self-sufficient for password resets, even when not using an external identity provider configured for single sign-on. In addition, the ability for a system administrator to configure an allowable email regex enables administrators to set up POC environments with real user emails without worrying that users will accidentally receive emails.
API Ease of Use Improvements
For API users of Data Refinery, new V2 GET APIs are now available for Projects, Sources, and Users. These APIs return objects in the same format as the input for their respective PUT endpoints. These new APIs eliminate the need to transform objects between API calls. New APIs are also implemented to easily add and remove Project-Source associations. These APIs allow users to add or remove a single Source from a Project without needing to query the Project first and modify the association list manually.
The existing (V1) APIs are still supported for backward compatibility.
Added Self-Deploy Guide and Templates
New documentation for self-deploying Data Refinery has been published. This includes step-by-step instructions to deploy Data Refinery to a new AWS environment. Additionally, Terraform template files are now available for download to speed up initial configuration and deployment.
Defect Fixes
- Resolved an issue where an invalid CRON string on one Background Task could prevent a separate Background Task from triggering.
- Resolved an issue where a Project could fail to create when it’s prefixed with a number, and not provide a good user error. A proper error is now returned.
- Resolved an issue where deleted Sources continued to be crawled by AWS Glue, increasing costs and causing scaling issues.
- Resolved an issue where the Navigation bar showed the user’s ID instead of their username.
- Resolved an issue where the default admin user cannot create Projects.
- Resolved a documentation issue where the OpenAPI client for
/api/tasks/repo/urlhad no response body.
Data Refinery 1.0 Release (November 2023)
Data Refinery 1.0 released.
Kingland is excited to announce the launch of Data Refinery! Our Data Refinery product continues Kingland’s pedigree of building software that allows our customers to solve complicated data problems.
Kingland’s Data Refinery product can be installed in our customer’s AWS accounts to aggregate, analyze, enrich, and operationalize data.
Read on to learn about all of Data Refinery’s excellent features.
Features
Streamlined Projects Creation
Connect all important Sources to one place to keep data organized and ready to query at a moment’s notice. Other key details include:
- The ability to govern and protect access based on permissions and roles.
- The opportunity to analyze data for accuracy, timeliness, and other key quality issues.
- Integrate with enterprise standard tools to scale data analysis, analytics, reporting, and data science.
Simple Source Curation
Easily upload data to Sources with only a few keystrokes. Query databases, spreadsheets, and web services effortlessly. Moreover, adding Sources in Data Refinery allows a user to:
- Bring together critical internal data or external data.
- Streamline data use across multiple Projects.
- Understand changes and versions of data.
- Blend, standardize, and optimize data sets for analytics and improvement initiatives.
- Remediate data quality issues with data science and data remediation tools.
Integrated Data Warehouse for Analyzing Data
Once data has been up-configured via the APIs or the Designer UI, query the data using Data Refinery’s integrated data warehouse. Data Refinery launches with a flexible data warehouse that provisions query capacity on-demand, so there’s no need to worry about large-scale capacity planning before implementing workloads. The data warehouse inherits permissions from the Secure Permissions Framework, so stored data is securely available to individual workloads. See Query the Data Warehouse for more information. Other benefits include:
- Data uploaded via the Designer UI is available near real-time in the data warehouse. New Sources and Versions may take slightly longer to appear.
- Each query executed in the warehouse receives its own pool of resources for executing the query, up to an administrator-defined limit.
- Inbound IP allow-lists allow for controlling who has access to the data warehouse, so SaaS or self-hosted BI tools can be allow-listed.
Integrated Background Tasks Function
Set up scheduled background jobs to automatically retrieve and update data at specific intervals, analyze data, or any other action necessary to ensure data in Data Refinery is up to date and useful. The Background Tasks function allows teams to automate jobs that need to happen repeatably without requiring an additional infrastructure team to set up resources to run the tasks. For Background Tasks, a user can:
- Create fully customizable tasks using Docker, with no restrictions on language or framework.
- Run tasks securely, with each task running in a separate instance with its own pool of resources.
- Run tasks on a scheduled basis, using well-known
cronsyntax for scheduling.
Easy Infrastructure-As-Code Templates for Self-Hosting
Running Data Refinery efficiently requires more than a single container; it requires a full architecture. To make it as easy to self-host as possible, Data Refinery 1.0 includes a complete Terraform module for deploying the whole architecture within AWS. This module consists of the ability to customize multiple attributes to ensure administrators can control cost vs performance tradeoffs. All configurations come standard with defaults suitable for production-level environments, but can also be configured to increase the scale of the system or down to reduce the code of the system. Other templates for self-hosting include:
- Scaling policies and resource policies for containers.
- Scaling policies and resource policies for the data warehouse.
- IP-based allow-lists for the data warehouse and APIs.
- Pre-defined alerts for monitoring the system.
User Management
Use Data Refinery APIs to manage users and grant permissions to Projects and Sources. Through the APIs, an administrator with the proper permissions can:
- Create a new user in Data Refinery.
- Inactivate an existing user for security.
- Assign users a User Project Role (UPR) for a Project.
Each user can also update their Data Refinery password and update their data warehouse password.
Single Sign-On Support
Administrators who don’t want to manage users individually, and want users to authenticate via a centralized Identity Provider (IdP) can enable Single Sign-On (SSO) using OpenID Connect (OIDC) support. See more information in the Single Sign-On documentation. Systems that have SSO enabled can:
- Automatically create new users when signing in via SSO.
- Sign in to Data Refinery using an Identity Provider instead of a password.
- Configure more than one Identity Provider for SSO.
Secure Permissions Framework
To ensure that critical data stays safe, Data Refinery delivers a permission framework to help with controlling access to data. Read more about the permissions framework in the Permissions and Roles documentation. Using this feature, an administrator with the proper permissions can:
- Grant users global permissions, such as the ability to create users, Projects, and Sources.
- Grant users per-project permissions, such as the ability to manage a single Project and grant permissions to a single Project.
Accessible API Documentation
Users have access to complete their Data Refinery goals through API requests. The availability to access the API Documentation provides options for users to complete their work and yield the best results in Data Refinery in an efficient way.
Approachable User Documentation
New users can explore the program and access the available documentation to understand how Data Refinery works. Moreover, users can rely on the documentation to:
- Learn how to create Projects and Sources.
- How to run Background Tasks in the UI and API.
- How to Query the Data Warehouse.
- Recognize different Permissions and Roles.
Users can review the documentation as often as they want to become acquainted with Data Refinery and find answers to their problems. Additionally, the implemented search functionality helps users find what they need faster. Documentation is self-hosted along with the refinery, ensuring users always have access to documentation that matches the Data Refinery version.
Feedback and Questions
Kingland values your input! Please continue to provide feedback on your experience and report any issues you encounter. Please get in touch with a Customer Service Lead at Kingland regarding any questions or needed assistance.
Stay tuned for more exciting updates in the future!